名词解释
LRU (Least Recently Used)
一种页面置换算法,选择最近最少使用的页面进行置换。它利用过去的访问记录预测未来的访问模式,较适合遵循时间局部性的场景。
FIFO (First In, First Out)
另一种页面置换算法,按照页面进入内存的先后次序进行替换。尽管简单易实现,但可能出现Belady 异常,即增加页框数反而增加缺页率。
TLB (Translation Lookaside Buffer)
一种用于加速虚拟地址到物理地址转换的高速缓存,存储最近使用的页表项。通过避免访问主存中的页表,提高内存访问效率。
虚拟地址
程序运行时使用的地址,由 CPU 生成,用于定位虚拟内存中的数据。在地址转换时,虚拟地址会映射到物理地址。
物理地址
计算机内存中的实际地址,CPU 通过内存管理单元(MMU)将虚拟地址转换为物理地址后,访问相应的内存位置。
虚页号 (VPN, Virtual Page Number)
虚拟地址中的高位部分,用于标识虚拟内存的某个页,与页表配合完成地址转换。
页框 (Page Frame)
物理内存被划分为固定大小的块,称为页框。虚拟内存中的页面被加载到页框中进行访问。
局部性原理
程序在运行时对内存的访问具有局部性,即访问行为集中在某些特定区域。
-
时间局部性:某数据被访问后短时间内可能会再次被访问,例如循环中的变量。
-
空间局部性:与某数据相邻的数据很可能被访问,例如数组或连续的指令。
SRAM (Static Random Access Memory)
静态随机存储器,利用触发器保存数据,不需要周期性刷新,速度快但成本高,主要用于缓存。
DRAM (Dynamic Random Access Memory)
动态随机存储器,利用电容存储数据,需要周期性刷新以防数据丢失,容量大且成本低,主要用于主存。
刷新
针对 DRAM 的操作,每隔一段时间通过重新写入数据来恢复电容电荷,确保存储数据不会因为泄漏而丢失。
存取时间
从发出访问命令到数据有效输出所需的时间,反映存储器的响应速度。
存取周期
两次独立存储访问之间的最小时间间隔。存取周期通常比存取时间更长,因为包括恢复时间等额外操作。
存储器带宽
单位时间内存储器可以传输的数据量,通常以字节每秒(B/s)为单位,反映存储器系统的吞吐能力。
第七章课后作业 3、4、5、6、10、17(1)(2)、23、24
计算机组成与系统结构(第3版) (袁春风、唐杰、杨若瑜、李俊) (Z-Library) (1), p.285
第三题:
每个内存条需要 8 个 DRAM 芯片。构建 2GB 的主存需要 4 个内存条。主存地址共有 32 位
高 6 位 用于芯片选择。行地址和列地址各占 13 和 13 位组成片内地址。
第四题:
4.假定用 64K×1 位的 DRAM 芯片构成 256K×8 位的存储器,要求回答下列问题。 (1) 所需芯片数为多少?画出该存储器的逻辑框图。 (2) 若每单元刷新间隔不超过 2ms,则产生刷新信号的间隔是多少时间?
总共 个芯片。
逻辑框图:
- 每组 8 个芯片存储一个字节(8 位),共 4 组,连数据线
- 地址线分为:
- 片选信号用于选择具体的组(需要 2 位片选信号)
- 片内地址有 6 位
刷新信号间隔=单元数刷新间隔时间=2ms/65,536≈30.5μs
第五题:
数据寄存器最少需要 16 位,地址寄存器最少应有 15 位,需要 个芯片。
第六题:
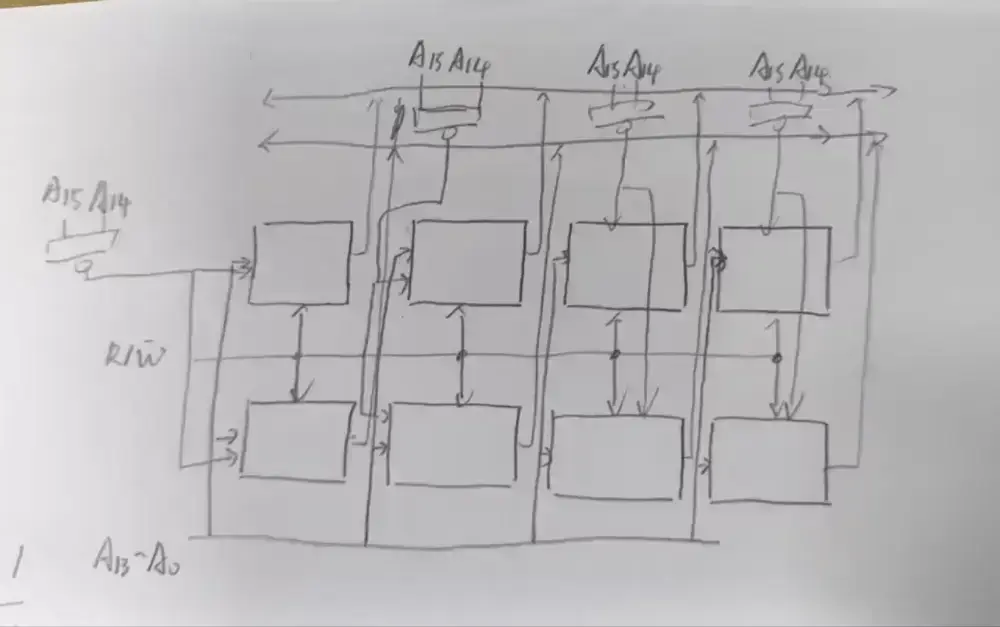
两块一组,分别连接数据线 D0 到 D7,地址线 A14A15 形成片选信号,A13 到 A0 为片内地址,读写和访存线连接每个芯片
16368 个
第十题:
(1) 几乎没有时间局部性和空间局部性
#include <stdlib.h>
#include <time.h>
void no_locality(int *array, int size, int iterations) {
srand(time(NULL));
for (int i = 0; i < iterations; i++) {
int random_index = rand() % size;
array[random_index] += 1; // 随机访问
}
}(2) 有很好的时间局部性,但几乎没有空间局部性
void good_time_no_space() {
int x = 0; // 频繁访问的变量
for (int i = 0; i < 100000; i++) {
x += i; // 重复访问x
}
}(3) 有很好的空间局部性,但几乎没有时间局部性
void good_space_no_time(int *array, int size) {
for (int i = 0; i < size; i++) {
array[i] += 1; // 线性访问数组
}
}(4) 空间局部性和时间局部性都好
void good_time_and_space(int *array, int size) {
for (int j = 0; j < 10; j++) { // 多次访问整个数组
for (int i = 0; i < size; i++) {
array[i] += j; // 线性访问 + 重复访问
}
}
}第十七题:
对三个程序段 ABC 中数组访问的时间局部性和空间进行分析比较:
cache 块大小为 8 个 int,有 8 个块。
A 程序内存连续访问,空间局部性最好,B 程序按列访问,按照直接映射每隔两次访问 struct 的时候都会访问同样的块,需要频繁唤入唤出,空间局部性较低,C 分开访问,局部性和 A 相同,但是耗时是 A 的两倍
画出主存中的数组元素和 cache 中行的对应关系图。
8C0H 直接映射到 cache 首行号为 0,每块两个数组元素,依次排列重叠下去
分别计算 3 个程序段 A、B、C 中的写操作次数、写不命中次数和写缺失率。