the Motherlode
一道 z3 算法题,做之前没想到考的真的细
题目大概是这样的:有个输入到 flag 中,然后有巨多的 if 判断,如果每个 byte 的条件判断成立了可以累加对应的分数
if (((flag[3] + flag[26]) & flag[32]) < (flag[9] + flag[25] - flag[28]) &&
((flag[15] - flag[16]) & flag[18]) <= 0x26 &&
(flag[14] + flag[23] * flag[2]) < ((flag[24] + flag[25]) * flag[26])) {
yeet(&scores); // 加1
}
if ((flag[2] * flag[37] - flag[43]) <= 0xC7u &&
(flag[47] - flag[41] + flag[11]) >= 0x3Du &&
(flag[49] + flag[33] - flag[5]) >= 0x4Du &&
((flag[13] * flag[46]) ^ flag[10]) >
(flag[23] - (flag[8] + flag[46]))) {
bump(&scores); // 加2
}
if (((flag[34] - flag[32]) * flag[6]) >= 0xF1u &&
((flag[20] + flag[55]) * flag[53]) <= 0xE0u) {
whack(&scores);
bump(&scores);
}最后检查分数要大于 1523
首先是要复习一下 arm nzcv 标志位
然后是这次没做出来的主要原因:IDA 的伪代码没有很好展现真实的数据大小拓展的过程(懒狗没看汇编导致的)。我们来简单的看一下汇编长什么样:
loc_DF64 ; CODE XREF: main+D5C0↑j main+D5DC↑j ...
LDRB W8, [SP,#0x60+flag+0x2F]
LDRB W9, [SP,#0x60+flag+0x2C]
LDRB W10, [SP,#0x60+flag+0x32]
ORR W8, W9, W8
EOR W8, W8, W10
CMP W8, #4
B.HI loc_E02C对应的是
((flag[44] | flag[47]) ^ (unsigned int)flag[50]) <= 4是放了三个 byte 到 32bits 寄存里里面,然后在 32bits 的寄存里里做按位或和异或运算,最后和字面值 4 比较
再看一个:
LDRB W9, [SP,#0x60+flag+4] ; Load from Memory
LDRB W10, [SP,#0x60+flag+7] ; Load from Memory
LDRB W8, [SP,#0x60+flag+9] ; Load from Memory
ADD W9, W10, W9 ; Rd = Op1 + Op2
MUL W9, W9, W8 ; Multiply
AND W9, W9, #0xFF ; Rd = Op1 & Op2
CMP W9, #0xCC ; Set cond. codes on Op1 - Op2
B.CC loc_E02C ; Branch
伪代码是这样的:
&& (unsigned __int8)((flag[7] + flag[4]) * flag[9]) >= 0xCCu这里是额外加上了一个取 8bits 的操作,在 IDA 的伪代码里面混在一起了, 容易认不出来,要很注意
接下来我们考虑怎么转化为 z3 公式。这里想了挺久策略的,最终还是把 IDA 的伪代码导出拿来用好搞一点
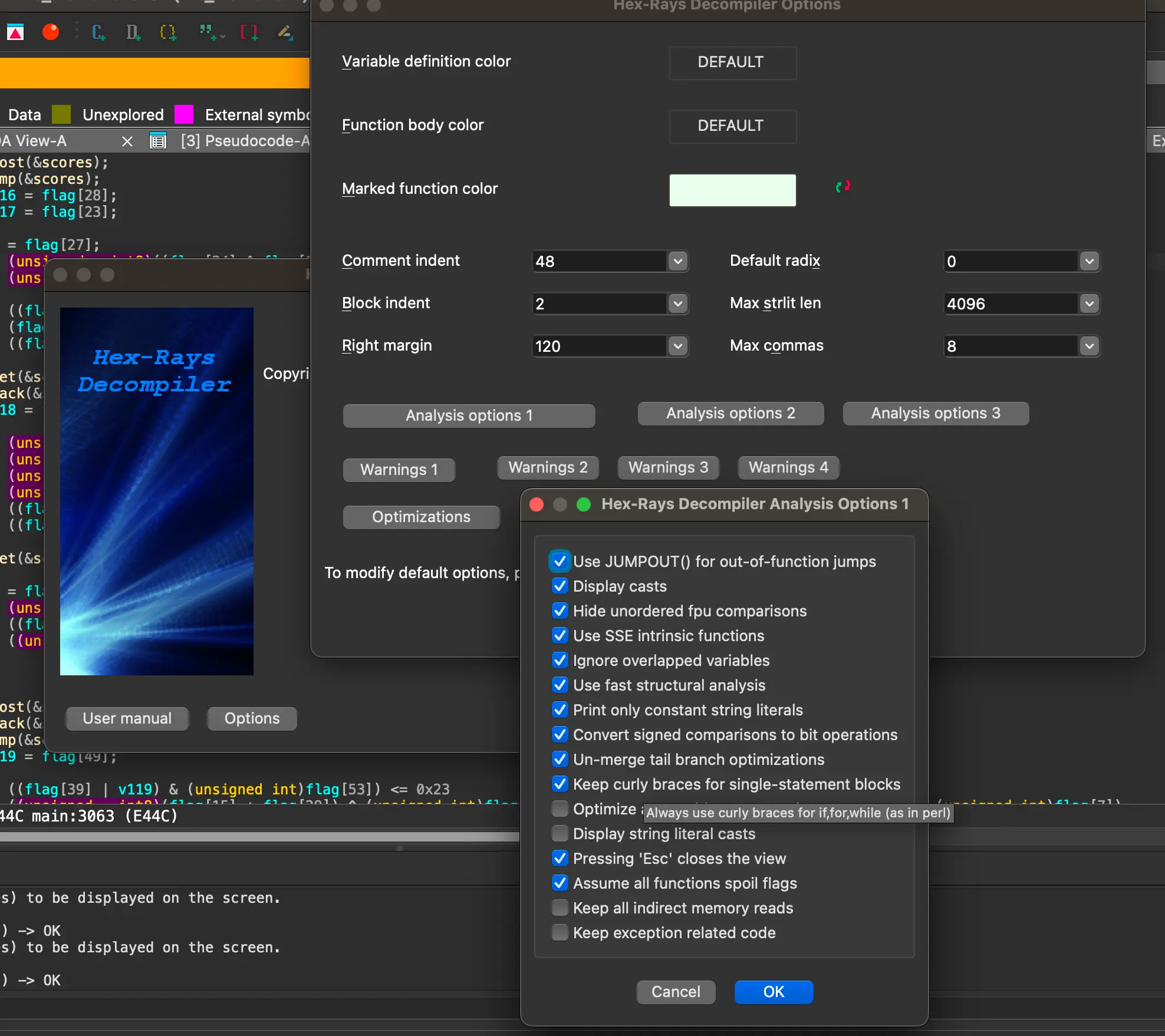
在反汇编插件设置里面把单行大括号打开,便于正则匹配。设置 flag 类型为 unsigned __int8 然后拖出来。在上面的设置里面也可以看到有个选项 use fast structual 把嵌套的 if 给优化成 and 连接的形式了,这个给后边脚本编写也提供了遍历(看了一圈 bn 发现不会用,还是回来调 ida 了)
同时也要注意到有这些东西存在:
v3 = flag[34];
v2 = v3;
...
((v3 | flag[53]) - flag[13]) &&
会有局部变量先赋值的情况(编译器流水线优化了),细心的同学会发现还有两次赋值的情况发生(就是再多了一个局部变量中转了),所以这里替换工作要做两次
v5 = flag[25];
v6 = flag[5];
if ((unsigned __int8)(flag[5] * flag[25] * flag[12]) >= 0xFDu &&
(unsigned __int8)((flag[23] ^ flag[26]) * flag[39]) <= 0x56u &&
(unsigned __int8)(((flag[7] + flag[40]) & flag[51]) + 52) <
(unsigned int)(unsigned __int8)(flag[28] * flag[40] * flag[42] -
8) &&
((unsigned __int8)(flag[29] & flag[46]) ^ (unsigned int)flag[33]) >=
0x56) {
whack(&scores);
v5 = flag[25];
v6 = flag[5];
}可以非常惊喜的发现这里的类型转换有个特点,就是小的转大的是括号打在类型上,大的转小的类型和后面的语句都会打上括号(巧合了,刚好方便了,正则真的好麻烦,ai 到现在也没有很好完成)。这里直接把转换到低位的用一个函数按位与函数实现
然后考虑题目本身一些约束,8 位乘 8 位,实际上最高不超过 16 位,所以这里取 16 位的 bitvec 就行。然后观察 flag 格式是 PCTF,里面是 16 进制数,这个约束又可以减很多时间。
写出转换脚本如下:
import re
from z3 import *
with open('../problem/p2_dump.cpp') as f:
content = f.read()
var_ass = re.finditer(r'(v\d+)\s*=\s*(.*);', content)
varmap = {}
for match in var_ass:
var_name = match.group(1)
ind = match.group(2)
varmap[var_name] = ind
for var_name, ind in varmap.items():
content = re.sub(r'\b'+re.escape(var_name)+r'\b', ind, content)
for var_name, ind in varmap.items():
content = re.sub(r'\b' + re.escape(var_name) + r'\b', ind, content)
# print('\n'.join(content.splitlines()[95:101]))
content = re.sub(r'(0x[0-9a-fA-F]+)u', r'\1', content)
content = re.sub(r'(\d+)u', r'\1', content)
content = re.sub(r'\(unsigned\ int\)', "", content)
content = re.sub(r'\(unsigned\ __int8\)', "tobyte", content)
# print('\n'.join(content.splitlines()[95:101]))
output = ""
funs = ['bump', 'whack', 'boost', 'yeet']
i=0
for ifmatch in re.finditer(r"if \(([\s\S]*?)\) {([\s\S]*?)}", content):
i+=1
if_state = ifmatch.group(1)
if_content = ifmatch.group(2)
clauses = if_state.replace('\n', "").split('&&')
condi = "And("+",".join(clauses)+")"
score_update = 0
for action in re.finditer(r'(\w+)\(&scores\)', if_content):
score_update += 1 << funs.index(action.group(1))
output += f"""
con_{i} = {condi}
o.add_soft(con_{i}, {score_update})
score += con_{i}*{score_update}
"""
output = """
from z3 import *
o = Optimize()
def tobyte(x):
return x & 0xff
flag = [BitVec(f"flag_{i}", 16) for i in range(56)]
score = 0
# flag 本身的约束
o.add(flag[0] == ord('P'))
o.add(flag[1] == ord('C'))
o.add(flag[2] == ord('T'))
o.add(flag[3] == ord('F'))
o.add(flag[4] == ord('{'))
o.add(flag[55] == ord('}'))
for i in range(5, 55):
o.add(Or(
And(flag[i] >= ord('0'), flag[i] <= ord('9')),
And(flag[i] >= ord('a'), flag[i] <= ord('f'))
))
# 软约束
""" + output + """
def update(model: ModelRef):
print(model.eval(score), bytes(model[c].as_long() for c in flag))
o.set_on_model(update)
o.check()
"""
with open("p2_gen.py", 'w', encoding="utf-8") as f:
f.write(output)
用到了 z3 最优化求解 的知识,这里在变最大值的时候输出可以很方便的查看和调试