https://www.cnblogs.com/zUotTe0/p/12729390.html
https://bbs.kanxue.com/thread-265330.htm
https://docs.hex-rays.com/user-guide/signatures/flirt/ida-f.l.i.r.t.-technology-in-depth
技术目标
- we only consider programs written in C/C++ 我们仅考虑用 C/C ++ 编写的程序
- we do not attempt to achieve perfect function recognition : this is theoretically impossible. Moreover the recognition of some functions may lead to undesirable consequences. For example, the recognition of the following function 我们不会尝试实现完美的功能识别:这在理论上是不可能的。此外,对某些功能的识别可能会导致不良后果。
- we only recognize and identify functions located in the code segment, we ignore the data segment. 我们仅识别并识别代码段中的功能,我们忽略了数据段。
- when a function has been sucessfully identified, we assign it a name and an eventual comment. We do not aim to provide information about the function arguments or about the behaviour of the function. 成功识别函数后,我们将其分配一个名称和最终评论。我们不打算提供有关函数参数或功能行为的信息。
- we try to avoid false positives completely. We consider that a false positive (a function wrongly identified) is worse than a false negative (a function not identified). Ideally, there should be no false positive at all. 我们试图完全避免误报。我们认为,假阳性(错误地识别的函数)比假阴性(未识别的函数)差。理想情况下,根本不应该有假阳性。
- the recognition of the functions must require a minimum of processor and memory resources. 对功能的识别必须需要最少的处理器和内存资源。
- because of the polyvalent architecture of IDA – it supports tens of very different processors – the identification algorithm must be platform-independent, i.e. it must work with the programs compiled for any processor. 由于 IDA 的多价体系结构(它支持数十个非常不同的处理器),标识算法必须独立于平台,即它必须与为任何处理器编译的程序配合使用。
- the main() function should be identified and properly labelled as the library’ startup-code is of no interest. 主函数应被识别并正确标记为库的启动代码。
技术难点
- 库函数庞大的大小要求搜索复杂度必须够小,空间耗费也必须够小
- 运行时重定位的操作让识别复杂度增加
- 不同编译器、编译器的优化、优化的程度等等都会影响最后的字节,使得简单的校验和识别效果不会很好
- 大量的短函数存在于标准库中
- 版权问题
原理
IDA flirt 通过对函数的关键特征进行静态库函数的识别,特征如下:
部分函数硬编码特征,如函数前 32 字节(可能变动的地方不匹配),采用字典树加速和缩小储存空间
558BEC0EFF7604..........59595DC3558BEC0EFF7604..........59595DC3 _registerbgidriver
558BEC1E078A66048A460E8B5E108B4E0AD1E9D1E980E1C0024E0C8A6E0A8A76 _biosdisk
558BEC1EB41AC55604CD211F5DC3.................................... _setdta
558BEC1EB42FCD210653B41A8B5606CD21B44E8B4E088B5604CD219C5993B41A _findfirst
对于前 32 个字节相同的情况,从从第 33 字节到第一个变体字节(variant byte)之间的字节开始计算 CRC16 作为第二个特征存储。但是计算范围是。如果这个范围内的字节完全相同,那么 CRC16 的值也会相同,无法区分函数。对于这种极少数的情况,会找一个位置让所有在这个叶子节点上的函数,这个位置上的字节都不同
A separate signature file is provided for each compiler. FLIRT 采用多阶段识别策略,首先识别程序的入口点和编译器(startup signature file 这个特殊的签名文件决定判断 like exe.sig),然后根据编译器选择合适的签名库进行函数识别。
Since we store all functions’ signatures for one compiler in one signature file, it is not necessary to discriminate the memory models (small,compact, medium, large, huge) of the libraries and/or versions of the compilers. 把一个编译器的所有 function 都存在同一个签名文件中了
这个设计决策的技术原理可以从编译原理和二进制兼容性角度来解释:
无需区分的根本原因:
-
函数签名的平台无关性
- 函数签名(返回类型、参数类型、调用约定等)在特定编译器的 ABI(Application Binary Interface)规范下具有稳定性
- 内存模型(small/compact 等)主要影响:
- 数据指针大小(如 far/near 指针)
- 默认内存段分配方式
- 栈/堆的布局策略
- 但不会改变函数参数在栈/寄存器中的传递规则(即调用约定)
-
编译器版本的二进制兼容
- 现代编译器(如 GCC/Clang/MSVC)的版本升级会严格保持:
- 相同优化级别下的函数 prologue/epilogue 结构
- 符号修饰(name mangling)规则
- 即使编译器版本更新,只要编译选项相同,生成的函数签名特征保持稳定
- 现代编译器(如 GCC/Clang/MSVC)的版本升级会严格保持:
-
符号解析的抽象层级
// 不同内存模型下的相同函数 // large 模式 void __far * alloc_large(unsigned __int32 size); // compact 模式 void __near * alloc_compact(unsigned __int16 size); /* 签名提取器会标准化为: void* alloc_*(unsigned size) */- 签名提取工具会对指针类型进行归一化处理
- 宽度差异(32/16 位)会被类型提升规则统一处理
-
模式选择的责任转移
- 内存模型的选择实际影响的是链接阶段(link-time),而非编译阶段:
Compile-time Link-time (生成.o/.obj) (选择内存模型) │ │ └─────符号特征一致─────────┘- 函数签名作为前端(front-end)特征,在编译完成后即固定
-
逆向工程的实际需求
- 在二进制分析场景中,不同内存模型的库文件具有:
- 相同的函数序言特征(prologue patterns)
- 相似的控制流图(CFG)结构
- 示例机器码对比:
Small模型函数入口 Large模型函数入口 ----------------- ----------------- 55 push ebp 55 push ebp 89 E5 mov ebp,esp 89 E5 mov ebp,esp 83 EC 10 sub esp,0x10 81 EC 00 sub esp,0x100 ↑ ↑ 仅栈分配大小差异 - 在二进制分析场景中,不同内存模型的库文件具有:
这种设计显著降低了特征库的维护成本,使跨模式/跨版本的二进制分析成为可能。但需要注意的前提是:该方案假设目标编译器严格遵循其 ABI 规范,且没有使用内存模型相关的特殊扩展语法(如 __based 指针等非标准特性)。
root@9b5b421b0020:/workspace# gcc -print-file-name=libc.a
/usr/lib/gcc/aarch64-linux-gnu/13/../../../aarch64-linux-gnu/libc.a
root@9b5b421b0020:/workspace# cp /usr/lib/gcc/aarch64-linux-gnu/13/../../../aarch64-linux-gnu/libc.a .
gcc -static ./static_call_cstdlib.c /usr/lib/gcc/aarch64-linux-gnu/13/../../../aarch64-linux-gnu/libc.a -o static_call_cstdlib
短于 4 字节且无外部引用的函数不生成签名,避免误识别。对 <ctype.h> 中的短函数,例外处理其引用的符号类型数组(计算数组的 CRC16 并存储)。
还有引用符号的特征: ^0011 ??_7Exception@CryptoPP@@6B@ 表示在函数 0x11 偏移处引用了符号
签名文件的生成
- 两阶段生成:
- 预处理库文件:使用工具
parselib处理.obj和.lib文件,生成包含函数模式、名称、CRC16 等信息的“模式文件”。 - 构建签名文件:通过工具
sigmake将模式文件转换为最终的签名文件,独立于输入文件格式,支持未来扩展。
- 预处理库文件:使用工具
- 压缩存储:使用 InfoZip 算法压缩签名文件,减少磁盘占用。
FLIRT 技术对库函数识别难点的解决方案
1. 库函数庞大导致的搜索复杂度和空间消耗
- 树结构存储签名:将函数签名按字节前缀组织为树状结构,合并公共前缀,极大压缩存储空间(如相同前导字节的签名共享节点)。
- 压缩签名文件:使用 InfoZip 算法压缩签名文件,减少磁盘占用。
- 高效匹配算法:树结构的层级匹配将时间复杂度从 O(n) 降低至接近 O(log n),支持快速搜索。
2. 运行时重定位的操作增加识别复杂度
- 变体字节标记:将重定位相关的地址字节标记为“变体字节”(如
E8/9A表示近/远调用),在签名生成和匹配时忽略这些字节,仅关注非变体部分的固定字节序列。 - CRC16 动态范围:CRC16 的计算范围从第 33 字节到第一个变体字节,避开重定位影响的区域。
3. 不同编译器、优化选项导致字节差异
- 按编译器分离签名文件:为每个编译器(如 MSVC、Borland)生成独立签名文件,避免跨编译器冲突。
- 人工筛选签名:签名文件创建者手动排除优化敏感的函数,确保签名通用性。
- 变体字节灵活性:优化可能改变的指令(如寄存器分配)被标记为变体字节,匹配时忽略差异。
4. 标准库中存在大量短函数
- 短函数过滤规则:长度小于 4 字节且无外部引用的函数不生成签名,避免误识别。
- 特殊短函数处理:对关键短函数(如
<ctype.h>中的函数),额外记录其引用的全局数据结构的 CRC16(如符号类型数组),作为辅助识别依据。
5. 版权问题
- 不存储原始字节:签名文件仅包含函数名、变体字节标记和 CRC16,不泄露原始库的代码内容。
- 知识产权保护:签名文件的生成过程无法逆向还原原始库代码,避免版权争议。
实际操作
https://docs.hex-rays.com/user-guide/signatures/makesig
获得一个带符号的,需要创建签名的文件 .a。可以用 debug 模式编译出来某个库之类的获得
使用对应的解析器去解析库文件,生成模式文件
.pat
- plb.exe:OMF 库的解析器(Borland 编译器常用)
- pcf.exe:COFF 库的解析器(微软编译器常用)
- pelf.exe:ELF 库的解析器(UNIX 系统常用)
- ppsx.exe:Sony PlayStation PSX 库的解析器
- ptmobj.exe:TriMedia 库的解析器
- pomf166.exe:Kiel OMF 166 对象文件的解析器
也可以使用
lib2pat把 lib 转为 pat用
sigmake将 pat 文件转为 sig 文件,在 ida 的 signiture 里加载进去就行了
这个方法我在 ida9 里面找不到对应的文件了,官方告诉我们其实可以直接通过打开 ida 界面导出,达到将这些信息移植到较新的二进制文件的目的
File → Produce File → Create SIG file 导出 sig,然后在 Signatures window 中导入这个信息
下面对整个过程进行模拟:
第一步编译一个静态库(有很多导出符号,这就是我们的目的)
int test2(int x){
char c[123] = "asdfasdfasfdasd241414fasfdsaf";
c[3]=0;
return x+3+c[9];
}
gcc --emit-static-lib slib.c -o slib.a
第二步调用这个静态库,然后去符号,模拟不知道库函数符号的情况
extern int test2(int x);
int main(){
int s=1313;
return test2(1313)+13;
}
gcc caller.c slib.a -o caller
strip caller
ida 打开 caller
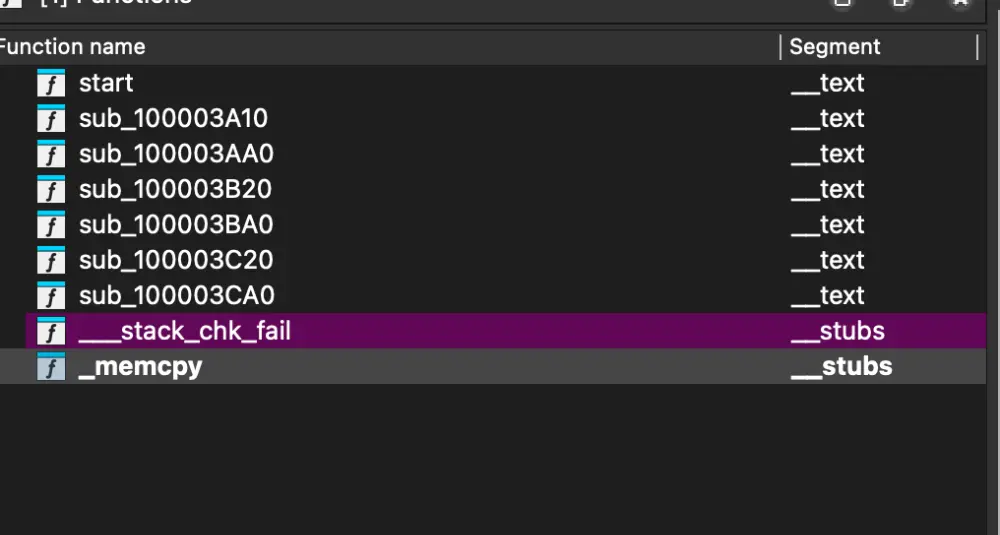 这时已经没有符号了,ida 打开没有去符号的 slib.a
这时已经没有符号了,ida 打开没有去符号的 slib.a
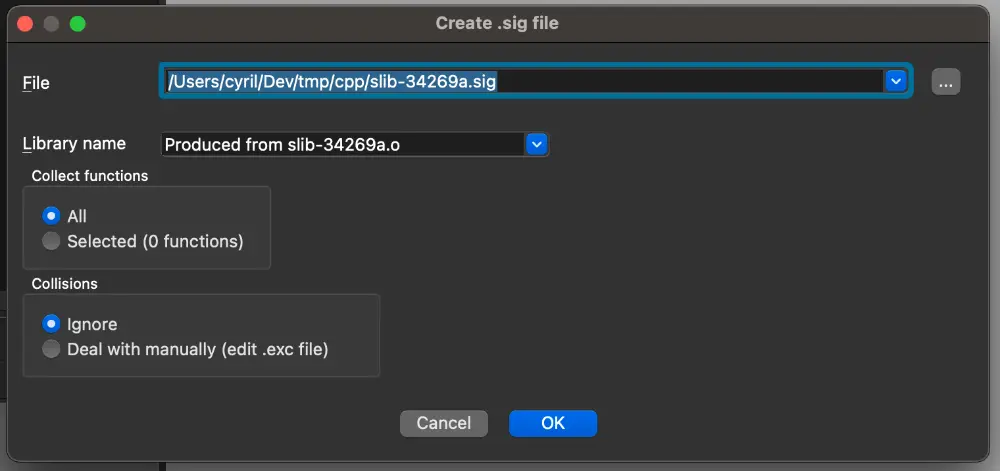
ida 会生成中间的 pat 文件和最后的 sig 文件
// slib.pat
FF4300D1E00B00B9E80B40B90809001108190271E8B79F1AA800003701000014 70 9ED5 0090 :00000000 _test
FF8302D1FD7B09A9FD430291........08....F9080140F9A8831FF8E00B00B9 08 952C 0080 :00000000 _test2 ^00000055 ___stack_chk_guard ^00000028 l___const.test2.c ^00000030 _memcpy ^0000006C ___stack_chk_fail ........21....91........FF430039E80B40B9080D0011E95BC0390801090BE80700B9A9835FF8........08....F9080140F9080109EBE8179F1A6800003701000014........E00740B9FD7B49A9FF830291C0035FD6
...
---
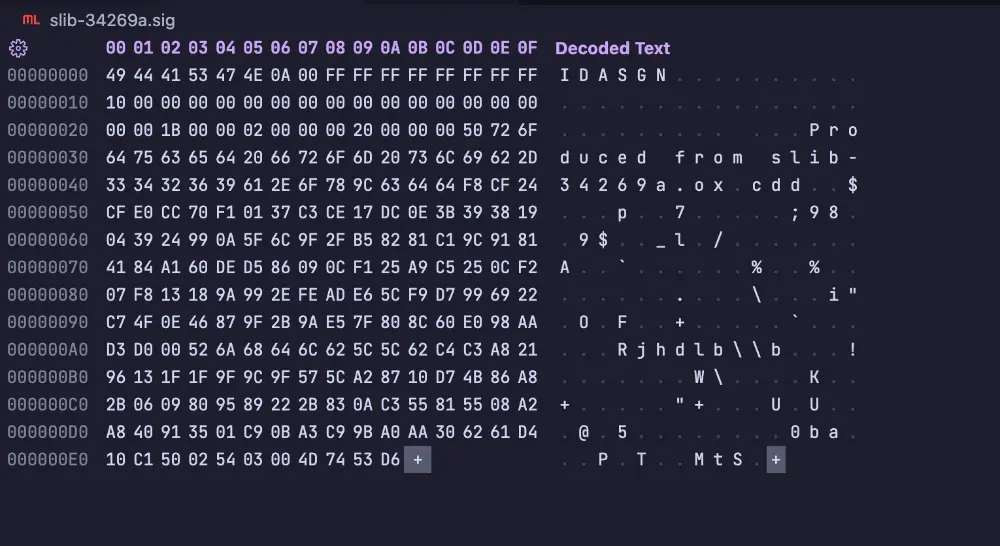
这个压缩率也太牛了?
右键打开菜单,这里有自带的一些 sig,再选择导入就行了
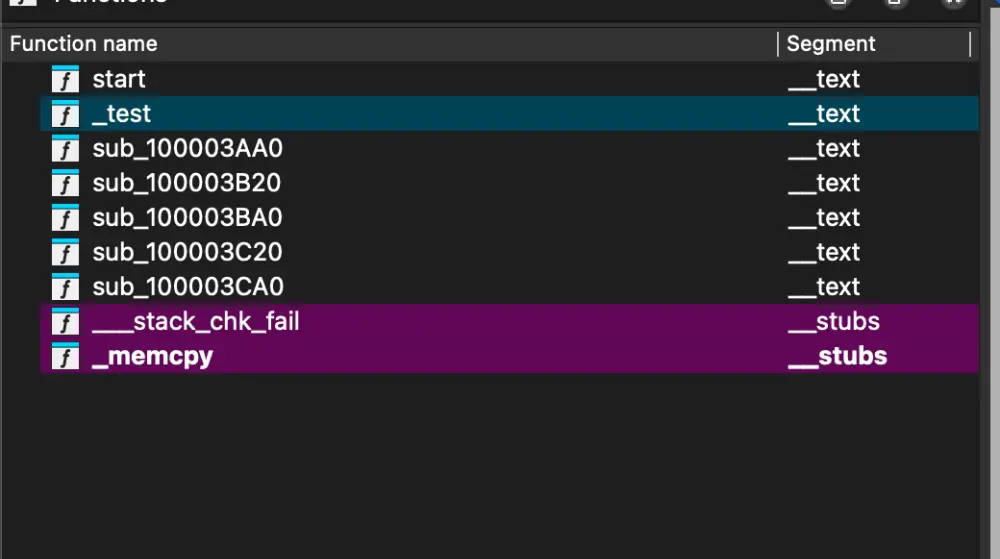
蓝色的是识别成功的函数,这里大部分识别失败了,猜测是因为其他函数太短了,就放弃识别了
实际操作二
_IO_init 3C D0F5 FD7BBFA9........A375BF520004004F2100032AFD03009142....B9010000B9
_IO_init_internal 3C D0F5 FD7BBFA9........A375BF520004004F2100032AFD03009142....B9010000B9