标题
人工智能在恶意代码分析中的应用研究综述
摘要
随着信息技术的发展,恶意代码成为网络安全领域重大威胁之一。恶意代码分析是识别和防御网络攻击的关键环节,但目前传统分析方法面临效率低、适应力差、高度依赖经验等问题。近年来,人工智能技术,特别是深度学习和大模型的发展,在恶意代码分析中展现出了巨大潜力。本文综述了人工智能技术在恶意代码分析中的应用,包括恶意代码的自动化检测、同源性分析,以及大模型在恶意代码分析中展现出的新态势。同时,指出了当前研究存在的不足并对未来恶意代码分析的发展方向进行了展望。
关键词:人工智能,恶意代码,自动化分析,机器学习,深度学习,大语言模型
引言
网络安全是信息时代的重要保障,而恶意代码是威胁网络安全的主要因素之一。随着恶意代码技术的不断更新迭代,传统的分析代码已经难以满足准确且快速识别恶意代码的需求。人工智能技术,尤其是深度学习和大模型的发展,为恶意代码分析提供了全新的解决方案。本文首先介绍了当前网络安全的现状及其面临的恶意代码威胁,然后概述了人工智能技术在提高恶意代码分析效率方面的潜力,并回顾了该领域的研究进展。
正文
- 恶意代码分析的基本概念
- 恶意代码定义和种类
- 恶意代码,也称为恶意软件或恶意程序,是指旨在对计算机系统、用户数据或网络造成损害的软件。
- 恶意代码按照其运行和传播特点主要分为两大类:第一类是需要宿主程序的恶意代码,这类恶意代码实际上是程序片段,它们不能独立存在,必须依附于某些特定的应用程序或系统环境中才能运行;第二类是能够独立运行的恶意代码,这类恶意代码是完整的程序,可以由操作系统直接调度和执行。此外,根据恶意代码是否具备自我复制的能力,还可以进一步细分为不能自我复制和能够自我复制的类型。具体来说,不能自我复制的恶意代码通常在调用宿主程序执行特定功能时被激活,而能够自我复制的恶意代码可能是需要宿主的程序片段(如病毒)或者是独立的程序(如蠕虫)。这些恶意代码类型包括计算机病毒、蠕虫、恶意移动代码、后门、特洛伊木马、Rootkit 以及组合恶意代码等,每一种都有其独特的特征和破坏方式。
- 传统文件分析方法
- 静态分析:
- 静态分析是一种不需要执行代码即可分析恶意软件行为的方法。其核心优势在于能够在安全的环境中,通过对代码本身的分析,获取关于恶意软件的详细信息。这种方法避免了直接运行恶意代码所带来的风险。静态分析的基础技术包括但不限于检查可执行文件的 PE 文件信息、字符串信息和脱壳技术。例如,通过使用 StudyPE 工具,分析人员可以获取文件的基本信息,如文件类型、大小、MD5 值等;而 Strings.exe 工具则用于提取程序中的字符串信息,帮助分析人员定位和理解程序的潜在行为。此外,静态分析的高级技术还包括对加壳恶意代码的脱壳处理,以及使用资源查看器(如 Restorator)来揭示恶意软件可能隐藏的其他恶意文件,从而为恶意软件的深入分析提供更多线索。
- 动态分析:
- 动态分析则是通过实际执行恶意代码,观察其对系统的影响来分析恶意软件行为的方法。这种方法能够揭示恶意代码的实际行为,包括文件操作、网络通信等。动态分析的基础技术涵盖了使用 Process Explorer 监控恶意代码的进程和子进程,Process Monitor 监听系统调用和操作,以及使用 IDA Pro 进行反汇编和分析恶意代码的执行流程。动态分析的关键在于创建一个安全的分析环境,以防止恶意代码对实际系统造成损害。这通常通过使用虚拟机和在线沙盒(如微步云沙箱)来实现,这些工具能够模拟真实的操作系统环境,同时隔离恶意代码,确保分析的安全性。
- 静态分析:
- 行为分析方法
- 符号化分析
- 符号执行(Symbolic Execution)是一种程序分析技术。其可以通过分析程序来得到让特定代码区域执行的输入。使用符号执行分析一个程序时,该程序会使用符号值作为输入,而非一般执行程序时使用的具体值。在达到目标代码时,分析器可以得到相应的路径约束,然后通过约束求解器来得到可以触发目标代码的具体值。
- 同源性分析
- 恶意代码同源性是指不同恶意代码是否来源于同一恶意代码集或由相同作者或团队编写,以及它们是否具有内在的关联性或相似性。相似性分析分为静态结构相似性和动态行为相似性两方面。静态结构相似性通过分析代码的源代码或二进制形式,利用程序控制流图等结构特征进行比较,但易受代码混淆和加壳技术的影响。动态行为相似性则基于恶意代码执行时的行为,通过监测系统状态改变和系统函数调用等来间接反映其行为,能减少静态分析中的干扰,但可能受恶意代码行为变异的影响。目前,静态和动态分析方法各有局限,许多研究开始采用动静结合的方法来提高恶意代码同源性分析的准确性。
- 流量分析
- 恶意软件经常通过网络流量传播,可以通过如 wireshark 等软件抓取网络流量,通过筛选端口、协议和 IP 地址,达到过滤分析恶意软件流量的目的。如查看恶意代码常常引发的 C2 流量是否处于活动状态通过截获流量包从而分析恶意代码。
- 符号化分析
- 恶意代码定义和种类
- 人工智能在传统分析方法中的应用
- 恶意代码的自动化检测
- 对于大量、多类型的代码检测需求,我们希望得到一种可靠、快速的扫描工具,快速判断恶意代码的存在。对于传统的如杀毒软件等软件,更多的是通过对文件本身的 Hash 和 String 特征和基于逻辑规则的检测方法分析恶意软件的运行时状态,提取关键路径作为判据。而由于其本地检测的机械性和内部模型的固定,使得免杀操作总是可以稳定的得到实现。而人工智能基于大数据得到的强推理聚类能力,能够很好的弥补这方面的缺点。1
- 人工智能的实现形式决定了对文件的分析只能局限在对特征的识别和推理上。从形式上总实现形式包括数据的表示、特征的提取、模型训练与决策四个步骤,下面将介绍四种事实可行的恶意代码提取特征方式 2
- 基于度量的特征包括 ELF 文件头、字符串、系统调用、操作码等
- ELF 文件相关属性包括架构名称、文件大小、外部库调用、加壳情况、联网情况等文件特征。34
- 而操作码是近年来新兴的检测模式,操作码指令很好的表示了程序运行时要执行的行为和函数调用等操作。通过对操作码的出现频率、序列、转化为图像处理等方式很好的表示了程序的实际行为。5 在已知文件为二进制代码的情况下,由于缺乏动态过程容易受到加壳等混淆手段的干扰,难以得到真正有效的操作码,需要提前进行尽可能的去混淆操作,和前面的已知特征结合分析。后来研究者通过采用异构特征选择方法,使用不同层次的语义特征,对抗垃圾代码混淆,更好的提高了准确性。6
- IR 中间层表示可以实现一种跨架构的分析,中间层的分析完整的保留了各自平台的独特实现,对跨平台利用漏洞的恶意代码分析具有一定意义。研究人员 7 基于 Vex 中间表示和一种基于控制流特征提取的动态规划算法训练了一个向量机恶意代码检测模型,较好的实现了对恶意代码的检测。
- 基于图或树的特征表示包括控制流图、函数调用图等
- 对于二进制文件静态分析,可以得到函数调用图,并使用 Graph2vec 对函数调用图进行图的嵌入。接着结合图嵌入特征和图结构特征,建立训练模型。Wu 8 等人在一个包含 10 万样本的大型数据集上进行实验,结果显示模型对支持向量机算法表现最佳,准确率高达 98.88%,但基于函数调用生成图的方法在应对海量数据的时候非常吃力。
- 控制流图相比函数调用图所包含的细节更多:控制流图的边表示跳转指令,如 jmp 、 call 等,能够更加细致的分析程序的执行路径、语句覆盖率、路径覆盖率等方面。研究人员 9 设计了一种基于此的函数特征相似度评估算法,事实证明其速度和准确率都有大幅提升。
- 基于函数流程图和调用图避免了对所有函数进行相似度计算,提升了总体的函数对比效率。10
- 基于序列的特征包括字节码、转换为图片等,相互依赖的特征
- 字符串特征具有良好的跨平台特性,可打印的字符串可以直接作为向量特征输入模型,包括 ELF 文件保留的符号名称、字符串常量,源代码层面的注释、层级结构等。但该特征需要结合其他特征才能取得较好的检测效果。
- 此外还有最原始的字节序列特征,同样通过转化为数值向量进行分类检测。
- 基于文件与外部环境之间的关系
- 得到 API 序列后对其进行特征工程 11,再用集成学习的方法对分类结果再选择最终得到分析检测结果,即得到是否为恶意代码和其具体类型
- API 典型的调用包括文件操作次数、文件 pid 跨度、文件运行时间跨度、文件产生进程数比的统计值、文件产生线程数线程出现次数比的统计值、文件调用 API 种类数、调用无重复 API 数统计值和信息熵统计值。 12
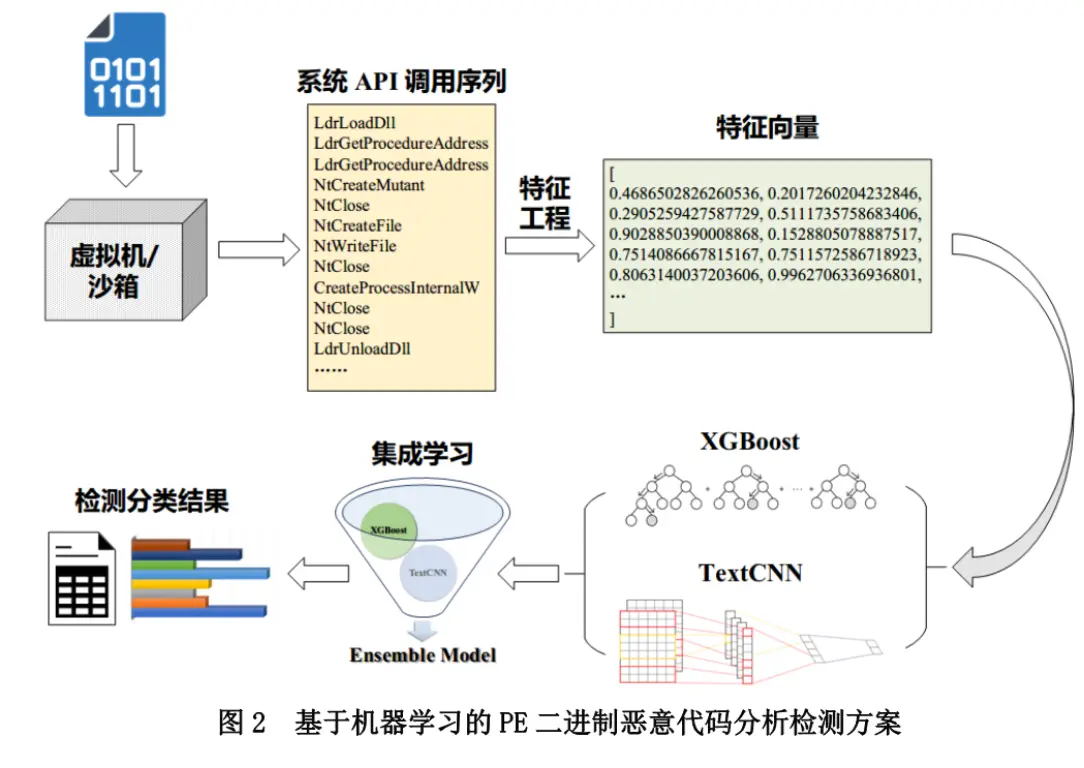
- 日本国家信息和通信技术研究所 13 通过在沙箱中使用 strace 得到 API 调用序列并用 N-gram 算法处理序列,但是该方法在部署和实际运行上仍存在问题,不少程序不能正常得到检测,其中原因之一是部分程序会采用反虚拟技术,即在虚拟环境中会放弃恶意行为,导致获取 API 失效 14。Zhao15 则用系统调用特征训练了 MDABP 基于平台即服务的检测模型。
- 由于系统调用时序特性的特点,李煳桦 16 采用了长短期记忆网络(LSTM)作为训练模型,基于循环神经网络动态检测恶意软件。通过该方法,能够有效提取软件在运行期间的特征模式。
- 基于补丁升级代码比较的分析
- 基于差分思想,该方式能够通过版本之间文件的差异性分析文件是否在更新中加入了恶意代码。武振华 17 等人通过对软件家族分类、谱系分析,再通过使用神经网络 DNN 判断相邻版本软件之间的差异性,最后对目标程序之中的差异代码进行深度恶意分析。由于分析的目标集中,该方法能够明显提升分析筛查的效率。
- 基于其他信道的恶意代码威胁发现
- 除了直接对恶意代码文件进行智能化分析,通过其他信道分析能够更加具有针对性,同时也是对文件分析的良好补充
- 基于网络流量的威胁发现
- 通过对通信的行为模式进行差异化分析,利用深度学习的方法,把传输的数据视为文本,进而使用如 DNN、RNN 等神经网络模型进行分析,进而确定威胁的来源。
- 基于主机数据的威胁发现
- 主机数据包括系统日志应用程序日志、安全日志等,主动记录运行文件的操作种类、操作时间、操作状态等。研究人员通过采用半监督方法,对异常数据进行启发式搜索,标记概率标签,再通过基于注意力的 GRU 神经网络提取日志数据的特征进行异常检测。
- 基于威胁情报的威胁发现
- 通过公开的威胁情报和组织内部的威胁情报,经过人工智能分析后能够整理出恶意代码的额外上下文信息,如目标对象、动机和使用的工具等,协助安全分析师更好的理解恶意代码的意图和行为,并做出更好的响应。
- 恶意代码的自动化检测
- 人工智能在分析恶意代码中的新应用
- 网络安全大模型的特化
- 基于 Transformer 的语言模型在自然语言处理中的出色表现,及其与高级编程语言的相似性,使得这些大模型在漏洞识别中的应用前景广阔。
- Claudia 研究了基于 Transformer 模型在 Java 漏洞多标签分类中的应用。Neuzz 采用了基于梯度的方法来增强模糊测试。通过使用 BERT 等 Transformer 模型,他们解决了现有漏洞检测数据集过小的问题,并显著提高了模型的性能。
- lilBuffaloEric18 等人通过针对网络安全领域特化,采用如 GitHub、Kaggle 、安全漏洞网站和公开的安全漏洞的数据集等等,结合人工标注和自我生成相结合的方法,构造了专门针对网络安全领域的对话数据。这种数据保证了模型能够理解和分析恶意代码。同时 AutoAudit 模型还和 ClamAV 等安全扫描工具进行耦合,搭建了一个安全扫描的平台,提高了模型的实用性。腾讯安全科恩实验室 19 首先通过搭建网络安全大模型评测平台来为安全大模型提供良好的测评能力,包括数据安全、应用安全等;再通过对涵盖安全博客、资讯文章、百科、安全书籍和安全论文等多种数据源的清洗和训练,显著提升了模型的效果。
- 大语言模型辅助分析,自然语义转化
- 在传统模式下,恶意代码通常是由专家拆解系统获取软件或硬件的行为流程和关键性数据来掌握其工作原理从而得到分析 20,这种方法指向性强,但是费时费力,需要操作者具有大量经验。现代形式的人工智能相当于逆向工程的复杂工具,能够大大降低许多类型逆向工程的操作成本和操作难度 21,同时具有更加快速、更加有全局观的特点
- 在传统逆向工程中,加密算法的软件识别通常通过加密的特征码来识别 22,这种方法需要拥有良好的数据源和软件较好的防混淆功能,但是一旦程序对数据再进行加密或者修改,这种方法便很难发挥作用。只能通过人工的经验积累来对程序的过程进行理解和对特征码复原来识别加密的方法 23。而人工智能的出现让这个过程能够通过大语言模型来完成,能够在速度和准确性方面超越人类专家 24。
- 运用人工智能辅助分析恶意代码,有助于分析人员理解没有明显符号标记或着组件映射关系的复杂系统的理解 25,从而快速理解和解耦程序的模块,确定分析目标。BinaryAI26 等二进制分析平台可以很好的完成此类工作。再通过例如批量恢复符号表 27 等技术恢复函数或变量的符号,用 Claude 等工具可以很快完成此类任务,并提供一些可能的测试建议。可以通过在提示词作用下通过与人类互动实现。事实证明,这种代码审计具有足够的能力独立审计代码并实现测试 28。
- 此外,进一步通过监督学习的方法能够用已经标记的数据来训练模型 29,使其能够识别系统的组件和所有接口、它们之间的功能操作和彼此的关联性 30;通过反复实验的过程逐步辅助完善对系统的理解 31;通过深度学习的方法能够最大程度利用 AI 聚类的特性,辅助分析高维数据,达到清洗、过滤、提纯的效果 24。
- 目前 LLM4Decompile 是唯一一个能直接基于反汇编进行分析并输出相应的 C 代码的模型,但是其精度不高,成功率仍然很低。而通过第三方组件先进行初步的反编译形成的 C 代码借助大模型进行可读性优化的方案具有良好的稳定性。但仍然受限于静态分析。对反编译形成的代码,通过大模型进行分析处理,并对其进行解释的可用性和准确性较高:32
- 大语言模型填补二进制软件分析空白
- 现有的软件组成分析技术已经足够成熟,对于完整的开源组件和代码,可以轻松被软件组成分析工具检测出来,然而仍有一部分由片段组成,传统的依赖分析无法并不适用。此外对于不开源的组件传统方法也无法进行检测。这一挑战可以通过对大模型进行预训练,利用大量的开源数据来解决。目前运行良好的有腾讯的 binaryai33
- 通过增量聚类方法实时更新恶意代码检测集
- 增量聚类是指一种能够实时处理和更新聚类结果的聚类算法,传统的聚类算法需要一次性的对所有数据梳理并存储,这与恶意代码的实时性和攻防平衡发展形势不符,而增量聚类能够逐个处理数据点并根据每个新的数据点来更新聚类的结果,使得增量聚类算法非常适合这种实时性非常强的恶意代码检测工作。
- 王毅 10 等人提出一种恶意代码增量聚类算法 GLIC,通过将网格密度聚类分析和线性判别发相结合,达到了实时对已有的恶意代码聚类结果更新的效果。
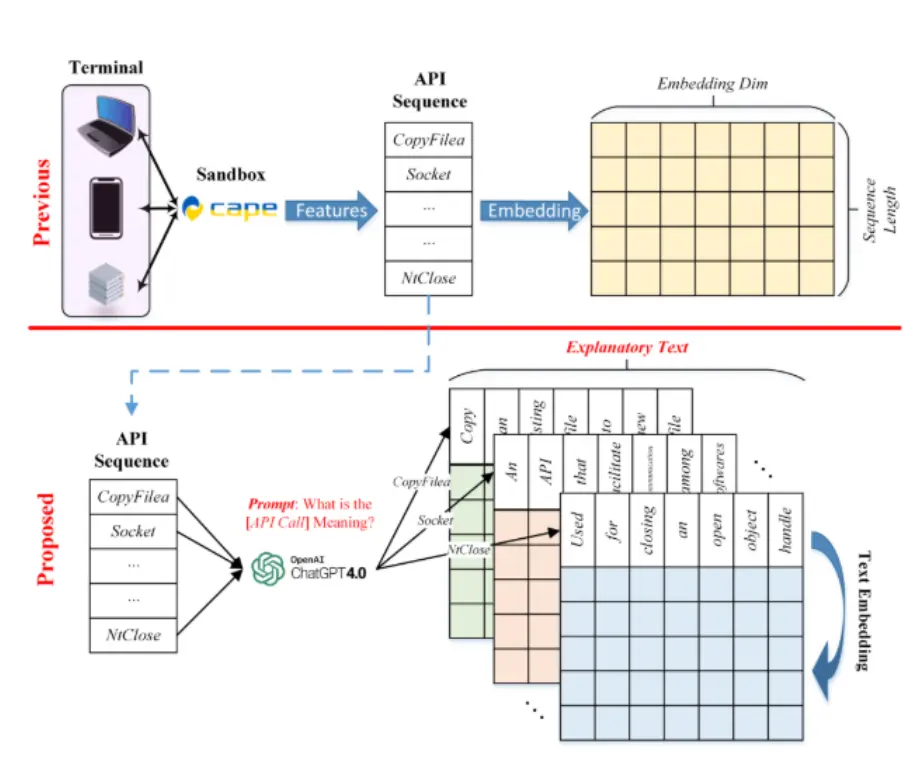
- 借助 GPT-4 提示内容生成 API 序列表征
- 广东省智能信息处理重点实验室团队 34 通过引入大语言模型 GPT-4 辅助恶意代码的动态分析,提出了一种新的恶意代码检测方法。该方法首先利用 GPT-4 为 API 序列中的每个 API 调用生成解释文本,然后使用预训练模型 BERT 获取解释文本的表征,从而得到 API 序列的表征。接着,设计了基于 CNN 的检测网络从表征中提取和学习特征,实现恶意代码的分类。
- 人工智能的同源性分析技术
- 现有的可疑代码同源性分析的工具较为复杂,非专业人员操作不便。利用人工智能技术自动化地识别和分析同源代码中的安全漏洞和可疑行为,可以极大提高代码安全性分析的效率。一种人工智能同源性分析技术,应由扫描模块,代码分析模块,人工智能模块组成,后者包含大数据单元,程序授权单元,智能判定单元和智能运行单元等。扫描模块负责计算机文件的扫描检查,并将可疑代码提交至人工智能模块。程序授权单元在获得授权后,通过智能运行单元打开代码分析模块,使代码分析模块上各个单元自动运转。在得到结果后,智能判定单元与作为代码分析数据库的大数据单元结合判断分析结果,从而使操作者的工作得到简化。35
- 基于生成对抗网络的恶意代码检测
- 恶意代码可视化技术原理:
- Nataraj 等研究人员提出了一种将恶意代码的二进制文件与可视化原理相结合的方法。利用 IDA Pro 等反汇编工具对恶意代码 PE 文件进行反汇编处理,将恶意代码转换成二进制文件。将得到的二进制文件作为输入文件,通过将原始二进制序列切割成 8bit 的子序列,再将子序列中的前 4 位和后 4 位看作十六进制数字,用这两个十六进制数字对应 256 级像素,实现二进制到灰度图的转换。36
- PE 文件中的 .text 节位于灰度图的头部位置,相同的恶意代码家族在包含核心程序代码的 .text 所在位置对应灰度图的纹理细节是相似的,可以作为判断恶意代码家族类别的主要依据。若属于同一家族的类别,则这些图像可根据相似性进行分类检测。
- 可视化处理方法不仅提高了恶意代码检测的准确性,而且为恶意代码分析提供了一种直观的视觉手段,已成为恶意代码分类检测的主要方法之一。
- 深度学习目标检测在可视化技术中的应用:
- 为提高所得恶意代码灰度图的分类精确度,选择采用深度学习的目标检测模型进行实验。使用传统的机器学习方法构建的目标检测算法往往面临两个问题。方面,由于穷举的候选框会大量无用窗口,拖慢检测速度;另一方面,特征提取方法多以研究者的经验而定,难以应对复杂多变的条件,使得检测的精度不够理想。
- 深度学习模型,例如 Faster R-CNN,在处理复杂图像分类问题时,相比传统方法,能够提供更高的精度和效率。因此,可以用来提高恶意代码灰度图分类的精确度。37
- 恶意代码可视化技术原理:
- 基于图卷积网络和改进 LSTM 的优化实时检测
- 目前,主流的恶意代码检测方法仍是基于带有签名匹配的静态分析和针对敏感行为的动态分析。然而,随着反检测技术的迅速发展, 混淆、加密、注入等技术层出不穷,对静态分析的准确性造成了较大影响,而动态监测虽然具有一定抵抗性,却需要依赖模拟环境实现对程序的行为监控和记录,且需要得到完整的程序行为记录后才能进行分析,时间和算力资源成本较高。
- 基于图卷积网络 GCN 的恶意代码分类方法,可以适应恶意代码特征的差异。38
- 基于 GCN 的恶意代码检测方法步骤如下。首先需要在沙箱环境中执行样本,以提取样本调用的 API 序列。随后生成有向循环图,将 API 作为图的顶点,API 之间的调用次数作为有向边的权重。使用基于马尔可夫链提取特征图。最后使用 GCN 分类器对提取的特征图进行分类。
- 基于 GCN 的恶意代码检测也存在一定的局限性。模型不能动态的获取新恶意样本的特征,故对未知样本的检测能力不强; 模型需要将样本置于沙箱中运行后才能获取到所有的 API 调用关系,故而花费的时间较长,无法进行实时检测。基于改进长短期记忆网络 LSTM 的未知恶意代码自优化实时检测系统可以解决这个问题。LSTM 集成了监视器、最大熵模型、BSAS 聚类模块和检测器等多个模块,: 首先,采用 API-Pair 的新数据结构,利用最大熵模型进行训练,以满足加权和自适应学习的需要。LSTM 同时实现了对未知恶意代码的实时检测和自优化。系统能够在检测过程中不断更新的 API 对图,自动学习和适应新的恶意代码特征,持续提升其对新型恶意代码的检测能力,从而有效地应对深度学习对抗攻击。39
- 网络安全大模型的特化
- 人工智能在分析恶意代码方面的不足
- 人工智能模型需要大量的数据进行训练,而对于最新的或者高度变异的恶意代码,其数据往往难以收集,这会导致模型可能无法对这些代码做出有效判断
- 目前绝大多数的人工智能系统在训练的时候都过分依靠某种特定的恶意代码特征,使得它们在面对具有高度反特征构造的程序的时候很容易失效,这些恶意代码能够通过修改代码结构来达到回避检测的目的
- 使用深度学习等人工智能算法,虽然可以较好识别出未知威胁,却往往知其然不知其所以然,算法模型缺乏可解释性,无法确定威胁来源 40
- 对人工智能技术在分析恶意代码未来的展望
- 目前对文件特征的人工智能分析手段已经比较成熟了
- 反检测技术如加壳、隐藏恶意行为等需要采取不同的措施应对,传统的人工方式能够较为优秀的解决这个问题,但是在目前的智能分析当中这仍是挑战。例如静态分析对于加密壳、多态混淆、打包、复杂调用链 32 和代码重排混淆技术 41 等仍然无法处理,而动态分析可以通过检测软件的行为规避这个问题,但程序的行为此时进入黑箱,动态检测对潜伏、高感知的程序仍然无效,且其复杂度变得无法负担。同时、恶意代码基于系统的特性导致对不同的操作系统需要采用不同的软件检测模型。目前大模型、多模态的技术给这种多过程、多选择的处理链提供了一种可行的解决方案,即通过对不同情况自调用不同模块并相互传递达到分层分析的目的。
- 大模型的出现,昭示着一种“从量变到质变”的过程。目前随着恶意软件的不同变种,基于历史样本的模型都存在被混淆的必然性。同时神经网络训练的模型与抽象的特征向量都趋近于黑箱,这对恶意代码的检测无疑是一种阻碍。怀着对未来的乐观心态,可以想象当参数的规模达到一定的时候,对于恶意代码调用的本质、对于推理的逻辑性和条理性得到极大的提升,分析的置信度大大提高,此时恶意代码的分析工作效果将得到巨大的提升。
结论
- 本文综述了人工智能技术在恶意代码分析中的应用,展示了其在恶意代码的辅助检测、自动化检测等方面的卓越成效。尽管人工智能技术在恶意代码分析领域取得了显著的进展,但仍面临数据收集困难、模型可解释性差等挑战。未来的研究需要进一步提高分析效率,优化模型的泛化能力和解释性,以更好地应对日益复杂的网络安全威胁。
Footnotes
-
Raju A D, Abualhaol I Y, Giagone R S, et al. A sruvey on cross-architectural IoT malwware threat hunting[J]. IEEE Access, 2021, 9: 91656-91709 ↩
-
刘奇旭,刘嘉熹,靳泽,等. 基于人工智能的物联网恶意代码检测综述 [J]. 计算机研究与发展,60(10):2234-2254. DOI:10.7544/issn1000-1239.202330450. ↩
-
Pa Y M P, Suzuki S, Yoshioka K, et al. IoTPOT: Analysing the rise of IoT compromises[C] //Proc of the 9th USENIX Workshop on Offensive Technologies (WOOT). Berkely, CA: USENIX Association, 2015:1-9 ↩
-
张吉昕. 基于深度学习的恶意软件特征分析与检测方法研究 [D]. 湖南: 湖南大学. ↩
-
Bilar D. Opcodes as predictor for malware[J]. International Journal of Elecatronic Security and Digital Forensics, 2007, 1 (2): 156-168 ↩
-
Vasan D, Alazab M, Venkattraman S, et al. MTHAEL: Crossarchitecture Iot malware detection based on neural network advanced ensemble learning[J]. IEEE Transactions on Computers, 2020, 69 (11): 16547-1667 ↩
-
Phu T N, Hoang L H, Toan N N, et al. CFDVex: A novel feature extraction method for detecting cross-architecture IoT malware[C] //Proc of the 10th Int Symp on Information and Communication Technology. New York: ACM, 2019: 248-254 ↩
-
Wu C Y, Ban T, Cheng S M, et al. IoT malware classification based on reinterpreted function-call graph[J]. Computers & Security, 2023, 125:103060 ↩
-
Xu, X.; Liu, C.; Feng, Q.; Yin, H.; Song, L.; and Song, D. 2017. Neural network-based graph embedding for crossplatform binary code similarity detection. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, 363–376. ACM. ↩
-
一种可行的基于机器学习的二进制恶意代码分析检测方案. 15-16 https://www.gsma.com/greater-china/wp-content/uploads/2021/02/AI-in-Security_cn.pdf ↩
-
https://www.cnblogs.com/gongyanzh/p/15800975.html 基于 API 调用的统计特征 ↩
-
Ban T, Jsawa R, Yoshioka K, et al. A cross-platform study on IoT malware[C] //Proc of the 11th Int Conf on Mobile Computing and Ubiquitous Network (ICMU). Piscataway, NJ: IEEE, 2018: 1-2 ↩
-
王天歌. 基于 API 调用序列的 Windows 平台恶意代码检测方法 [D]. 北京: 北京交通大学. https://d.wanfangdata.com.cn/thesis/D02532480 ↩
-
Zhao Yang, Kuerben A. DMABP: A novel approch to detect cross-architecture IoT malware based on PaaS[J]. Sensors, 2023,23 (6): 3060 ↩
-
李煳桦. 基于深度学习的恶意软件检测方法研究 [D]. 黑龙江: 哈尔滨工业大学. ↩
-
[1] 武振华. 软件供应链污染检测技术研究 [D].战略支援部队信息工程大学.DOI: 10.27188/d.cnki.gzjxu.000053. 57 ↩
-
https://github.com/ddzipp/AutoAudit AutoAudit- 网络安全大模型 ↩
-
https://keenlab.tencent.com/zh/2024/04/11/2024-SecCorpus0411/ SecCorpus: 构建安全领域大模型数据的技术实践 ↩
-
https://zh.wikipedia.org/zh-hans/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD%E8%BE%85%E5%8A%A9%E4%B8%8B%E7%9A%84%E9%80%86%E5%90%91%E5%B7%A5%E7%A8%8B ↩
-
Bayern, Shawn, Reverse engineering (by) artificial intelligence, Research Handbook on Intellectual Property and Artificial Intelligence (Edward Elgar Publishing), 2022-12-13: 391–404 [2023-07-06], ISBN 978-1-80088-190-7, doi:10.4337/9781800881907.00029 ↩
-
常见加密方法特征识别 https://www.cnblogs.com/ikdl/p/15802507.html ↩
-
- Eilam, Eldad. Reversing: secrets of reverse engineering Nachdr. Indianapolis, Ind: Wiley. 2005. ISBN 978-0-7645-7481-8.
-
Abbott, Ryan (编). Research handbook on intellectual property and artificial intelligence. Research handbooks in intellectual property. Cheltenham Northampton, MA: Edward Elgar Publishing. 2022. ISBN 978-1-80088-189-1. ↩
-
BinaryAI https://www.binaryai.net ↩
-
https://bbs.kanxue.com/thread-278332.htm 《AI 辅助下的逆向工程》之:AI 给 sub_xx() 函数批量起名 ↩
-
https://mp.weixin.qq.com/s?__biz=MzkyMTI0NjA3OA==&mid=2247492021&idx=1&sn=3ec65e63f1efbbd1324a858899c211a5&chksm=c18421a4f6f3a8b2525c5fac0bc0979ce55cbd539148c8c743e663a588332fa7be2ebc0def07&scene=132#wechat_redirect AI 辅助代码审计应用与安全风险 ↩
-
刘奇旭,刘嘉熹,靳泽,等. 基于人工智能的物联网恶意代码检测综述 [J]. 计算机研究与发展,60(10):2234-2254. DOI:10.7544/issn1000-1239.202330450. ↩
-
Tonella, Paolo; Torchiano, Marco; Du Bois, Bart; Systä, Tarja. Empirical studies in reverse engineering: state of the art and future trends. Empirical Software Engineering. 2007-09-20, 12 (5): 551–571. ISSN 1382-3256. doi:10.1007/s10664-007-9037-5 ↩
-
Horváth, Imre (编). Tools and methods of competitive engineering: proceedings of the Tenth International Symposium on Tools and Methods of Competitive Engineering - TMCE 2014, May 19 - 23, Budapest, Hungary. Delft: Faculty of Industrial Design Engineering, Delft University of Technology. 2014. ISBN 978-94-6186-177-1. ↩
-
https://www.secfree.com/news/industry/10701.html 大模型在二进制安全领域中的应用 ↩ ↩2
-
https://www.binaryai.cn/ binaryai ↩
-
Pei Yan, Shunquan Tan, Miaohui Wang, Jiwu Huang: Prompt Engineering-assisted Malware Dynamic Analysis Using GPT-4 https://arxiv.org/pdf/2312.08317.pdf ↩
-
刘奇旭,刘嘉熹,靳泽,等. 基于人工智能的物联网恶意代码检测综述 [J]. 计算机研究与发展,60(10):2234-2254. DOI:10.7544/issn1000-1239.202330450 ↩
-
梁镇. 基于生成对抗网络的恶意代码检测研究 [D].沈阳理工大学.DOI:10.27323/d.cnki.gsgyc.000204. ↩
-
梁镇. 基于生成对抗网络的恶意代码检测研究 [D].沈阳理工大学.DOI:10.27323/d.cnki.gsgyc.000204. ↩
-
李善玺. 基于机器学习的未知恶意代码自优化实时检测技术研究 [D].兰州大学.DOI:10.27204/d.cnki.glzhu.000051. ↩
-
李善玺. 基于机器学习的未知恶意代码自优化实时检测技术研究 [D].兰州大学.DOI:10.27204/d.cnki.glzhu.000051. ↩
-
刘宝旭,张方娇,刘嘉熹,等.人工智能在网络攻防领域的应用及问题分析 [J].中国信息安全 (06):32-36. ↩
-
Sharif et al., 2009 ↩