一、样本标签确认(VirusTotal)
使用 python 完成自动化操作,结果保存成 csv 格式:
将样本文件放在 ./sample 文件夹下
API 格式介绍网站为 https://docs.virustotal.com/reference/files-scan
首先需要提交文件:
import requests
url = "https://www.virustotal.com/api/v3/files"
files = { "file": ("0d49388ec8384d654d8e3383e8ea606c.apk", open("0d49388ec8384d654d8e3383e8ea606c.apk", "rb"), "application/vnd.android.package-archive") }
headers = {
"accept": "application/json",
"x-apikey": "API_KEY"
}
response = requests.post(url, files=files, headers=headers)
print(response.text)返回类似于
{
"data": {
"type": "analysis",
"id": "MGQ0OTM4OGVjODM4NGQ2NTRkOGUzMzgzZThlYTYwNmM6MTc0Mjc0MTgyOA==",
"links": {
"self": "https://www.virustotal.com/api/v3/analyses/MGQ0OTM4OGVjODM4NGQ2NTRkOGUzMzgzZThlYTYwNmM6MTc0Mjc0MTgyOA=="
}
}
}然后需要获取文件报告
import requests
url = "https://www.virustotal.com/api/v3/files/MGQ0OTM4OGVjODM4NGQ2NTRkOGUzMzgzZThlYTYwNmM6MTc0Mjc0MTgyOA%3D%3D"
headers = {
"accept": "application/json",
"x-apikey": "API_KEY"
}
response = requests.get(url, headers=headers)
print(response.text)返回结果是一个 json
{
"data": {
"id": "NGQ3ZGI3NjFjYzk0Mjg3ZWRmMmE3MmJhZTAzZTA2NGY6MTc0Mjc0NDU2MQ==",
"type": "analysis",
"links": {
"self": "https://www.virustotal.com/api/v3/analyses/NGQ3ZGI3NjFjYzk0Mjg3ZWRmMmE3MmJhZTAzZTA2NGY6MTc0Mjc0NDU2MQ==",
"item": "https://www.virustotal.com/api/v3/files/aeff479483af8badfb0f574b16598caa27c6767fafb62b381c67454730c90696"
},
"attributes": {
"results": {
"Bkav": {
"method": "blacklist",
"engine_name": "Bkav",
"engine_version": "2.0.0.1",
"engine_update": "20250323",
"category": "undetected",
"result": null
},
...
},
"stats": {
"malicious": 37,
"suspicious": 0,
"undetected": 24,
"harmless": 0,
"timeout": 7,
"confirmed-timeout": 0,
"failure": 0,
"type-unsupported": 9
},
"date": 1742744561,
"status": "completed"
}
},
"meta": {
"file_info": {
"sha256": "aeff479483af8badfb0f574b16598caa27c6767fafb62b381c67454730c90696",
"md5": "4d7db761cc94287edf2a72bae03e064f",
"sha1": "cf1652cdcaa16042d40a11e2d2d4923604019cd1",
"size": 4240055
}
}
}之后通过编写 python 自动化脚本得到所有样本的报告关键信息,存储为 CSV 格式。这里需要注意每分钟提交不超过四次,而且每天有限额,而且上传文件会先排队,需要有一个轮询的逻辑。这里一分钟检查一次。
import os
import time
import requests
import csv
import hashlib
# 配置参数
API_KEY = "3e39ab239f6402a091cfe99faafb31ba1858b1d75e5696dd4180c6aa5532a16b"
SAMPLE_DIR = "./sample"
OUTPUT_CSV = "virustotal_report.csv"
MAX_RETRIES = 5 # 最大重试次数
API_DELAY = 60
def get_file_hash(filepath):
"""计算文件的SHA256哈希"""
sha256 = hashlib.sha256()
with open(filepath, "rb") as f:
while chunk := f.read(4096):
sha256.update(chunk)
return sha256.hexdigest()
def upload_file(filepath):
"""上传文件到VirusTotal并返回分析ID"""
url = "https://www.virustotal.com/api/v3/files"
headers = {"x-apikey": API_KEY}
try:
with open(filepath, "rb") as f:
files = {"file": (os.path.basename(filepath), f)}
response = requests.post(url, files=files, headers=headers)
response.raise_for_status()
# print("Getting upload response: ", response.text)
return response.json()['data']['id']
except Exception as e:
print(f"Upload failed for {filepath}: {str(e)}")
return None
def get_analysis_report(analysis_id):
"""轮询获取完整分析报告"""
url = f"https://www.virustotal.com/api/v3/analyses/{analysis_id}"
headers = {"x-apikey": API_KEY}
retries = 0
while retries < MAX_RETRIES:
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
data = response.json()
# print("Getting report: ", response.text)
status = data['data']['attributes']['status']
print(f"当前分析状态: {status}") # 调试信息
if status == 'completed':
attributes = data['data']['attributes']
stats = attributes.get('stats', {})
results = attributes.get('results', {})
# 构建结构化报告
return {
"malicious": stats.get("malicious", 0),
"suspicious": stats.get("suspicious", 0),
"total_engines": sum(stats.values()),
"vendors": [
f"{k}:{v['result']}"
for k, v in results.items()
if v.get('category') == 'malicious'
]
}
except KeyError as e:
print(f"关键字段缺失: {str(e)}")
return None
except requests.exceptions.HTTPError as e:
print(f"API请求失败: {e.response.status_code}")
if e.response.status_code == 404:
print("分析ID不存在,终止重试")
break
time.sleep(API_DELAY)
retries += 1
print("超出最大重试次数")
return None
def process_samples():
"""批量处理样本"""
with open(OUTPUT_CSV, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow([
'filename', 'malicious', 'suspicious',
'total_engines', 'result', 'detected_vendors',
'report_link', 'sha256'
])
for filename in os.listdir(SAMPLE_DIR):
if not filename.endswith('.apk'):
continue
filepath = os.path.join(SAMPLE_DIR, filename)
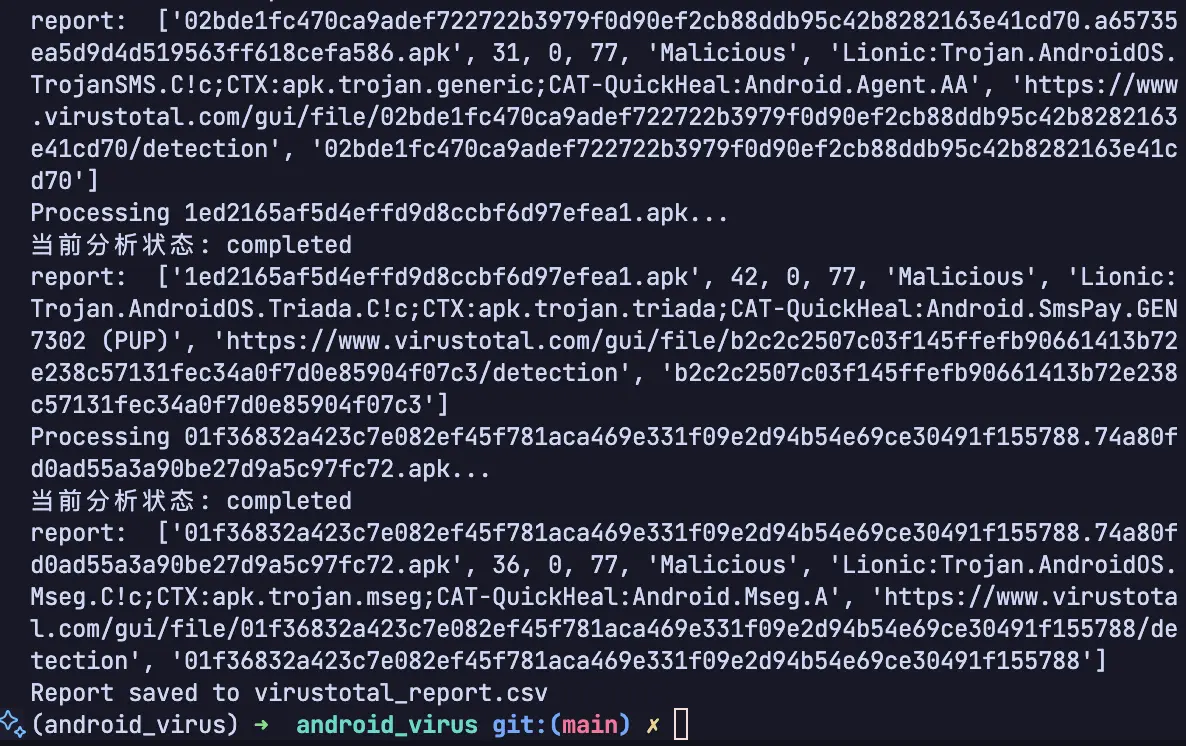
print(f"Processing {filename}...")
# 步骤1: 上传文件
analysis_id = upload_file(filepath)
if not analysis_id:
print(f"无法获取 {filename} 的id")
continue
time.sleep(API_DELAY)
# 步骤2: 获取报告
report = get_analysis_report(analysis_id)
if not report:
print(f"无法获取 {filename} 的完整报告")
continue
file_hash = get_file_hash(filepath)
row = [
filename,
report.get('malicious', 0),
report.get('suspicious', 0),
report.get('total_engines', 0),
'Malicious' if report.get('malicious', 0) > 0 else 'Benign',
";".join(report.get('vendors', [])[:3]), # 最多显示三个厂商
f"https://www.virustotal.com/gui/file/{file_hash}/detection",
file_hash
]
writer.writerow(row)
print("report: ", row)
time.sleep(API_DELAY)
if __name__ == "__main__":
process_samples()
print(f"Report saved to {OUTPUT_CSV}")
最终得到
filename,malicious,suspicious,total_engines,result,detected_vendors,report_link,sha256
25be589140f73949124f08759ab5bb57b126396f1401e3bfbfdc5e5c056e0d03.25e35ca260d2ae765cfbe139277fe473.apk,42,0,77,Malicious,Lionic:Trojan.AndroidOS.KungFu.C!c;CAT-QuickHeal:Android.Kungfu.L;Skyhigh:Artemis!Trojan,https://www.virustotal.com/gui/file/25be589140f73949124f08759ab5bb57b126396f1401e3bfbfdc5e5c056e0d03/detection,25be589140f73949124f08759ab5bb57b126396f1401e3bfbfdc5e5c056e0d03二、AndroGuard 环境配置(macOS)
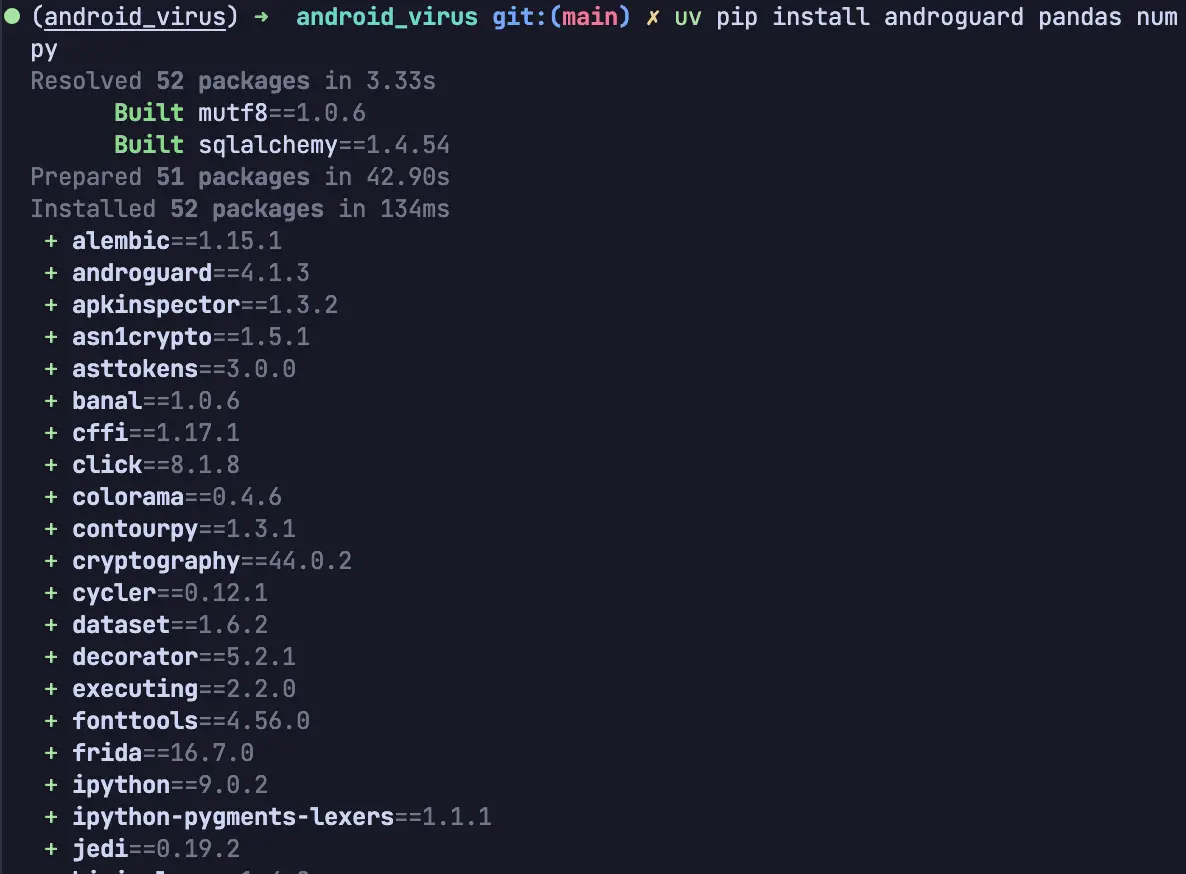
brew install python
python3 -m venv androenv
source androenv/bin/activate
pip install androguard pandas numpy如使用 uv 配置环境
[project]
name = "android-virus"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.13"
dependencies = [
"androguard>=4.1.3",
"pandas>=2.2.3",
"requests>=2.32.3",
"scikit-learn>=1.6.1",
]
三、特征提取脚本
提取证书、权限和字符串信息
import os
from androguard.misc import AnalyzeAPK
import pandas as pd
import re
# 预定义敏感特征库
DANGEROUS_PERMISSIONS = {
'SEND_SMS', 'RECEIVE_SMS', 'READ_SMS', 'WRITE_SMS',
'ACCESS_FINE_LOCATION', 'ACCESS_COARSE_LOCATION',
'READ_CONTACTS', 'WRITE_CONTACTS', 'CALL_PHONE'
}
SENSITIVE_API_PATTERNS = {
'telephony': ['Landroid/telephony/', 'getDeviceId', 'getSimSerialNumber'],
'location': ['Landroid/location/', 'requestLocationUpdates'],
'sms': ['Landroid/telephony/SmsManager', 'sendTextMessage'],
'contact': ['Landroid/provider/ContactsContract', 'getContactList']
}
def analyze_apk(apk_path)
a, d, dx = AnalyzeAPK(apk_path)
# 权限分析
all_perms = a.get_permissions()
dangerous_perms = [p for p in all_perms if any(dp in p for dp in DANGEROUS_PERMISSIONS)]
# API调用分析
sensitive_apis = {}
for category, patterns in SENSITIVE_API_PATTERNS.items():
methods = dx.find_methods(*patterns)
sensitive_apis[f"api_{category}"] = len(methods)
# 证书分析
cert_info = a.get_certificates()[0].get_issuer() if a.get_certificates() else {}
# 动态行为检测
dynamic_loading = len([clazz for clazz in dx.get_classes() if 'BaseDexClassLoader' in clazz.get_superclassname()])
# 字符串特征
suspicious_strings = re.findall(r'(http|ftp|ssh)://\S+', a.get_android_manifest_axml().get_xml())
return {
"filename": os.path.basename(apk_path),
"permissions": ",".join(all_perms),
"dangerous_perms_count": len(dangerous_perms),
"activities": len(a.get_activities()),
"services": len(a.get_services()),
"receivers": len(a.get_receivers()),
**sensitive_apis,
"cert_issuer": cert_info.get('O', 'Unknown'),
"dynamic_loading": dynamic_loading,
"suspicious_urls": len(suspicious_strings)
}
# 批量处理APK
features = []
for apk_file in os.listdir("apk_folder"):
if apk_file.endswith(".apk"):
try:
features.append(analyze_apk(os.path.join("apk_folder", apk_file)))
except Exception as e:
print(f"Error processing {apk_file}: {str(e)}")
pd.DataFrame(features).to_csv("enhanced_features.csv", index=False)四、自动化大模型判断
import csv
import requests
import time
API_KEY = "sk-0fa29c110d354cb1bc93b6c1cfe2be59"
API_URL = "https://api.deepseek.com/v1/chat/completions"
MODEL_NAME = "deepseek-reasoner"
PROMPT_TEMPLATE = """
根据下面的内容判断样本是否恶意,同时注意不要误报,遵循【误报最小化原则】:
【要求的权限】
{permissions}
【程序中出现的URL】
{suspicous_urls}
【证书信息】
{cert_issuer}
请根据以上信息判断样本是否恶意,然后填写结论。仅填写(恶意/正常):
"""
def main():
with open('local_abstract.csv', 'r') as csvfile, \
open('result.csv', 'w', newline='', encoding='utf-8') as outfile:
reader = csv.DictReader(csvfile)
writer = csv.DictWriter(outfile, fieldnames=['filename', 'prediction'])
writer.writeheader()
for row in reader:
# 解析数据
permissions = row['permissions'].split(',')
suspicious_urls = row['suspicous_urls'].split(',')
cert_issuer = row['cert_issuer']
# 构造prompt
content = PROMPT_TEMPLATE.format(
permissions=permissions,
suspicous_urls=suspicious_urls,
cert_issuer=cert_issuer
)
print("=====================================")
print(f"Analyzing {row['filename']}...")
print(content)
# API调用
response = requests.post(
API_URL,
headers={"Authorization": f"Bearer {API_KEY}"},
json={
"model": MODEL_NAME,
"messages": [{"role": "user", "content": content}],
"temperature": 0.1
},
timeout=120
)
response.raise_for_status()
data = response.json()
prediction = data['choices'][0]['message']['content'].strip()
reasoning = data['choices'][0]['message']['reasoning_content'].strip()
print(f"Reasoning: {reasoning}")
# 写入结果
writer.writerow({
'filename': row['filename'],
'prediction': 1 if '恶意' in prediction else 0
})
# 打印日志
print(f"Processed: {row['filename']} -> {prediction}")
time.sleep(1)
if __name__ == "__main__":
main()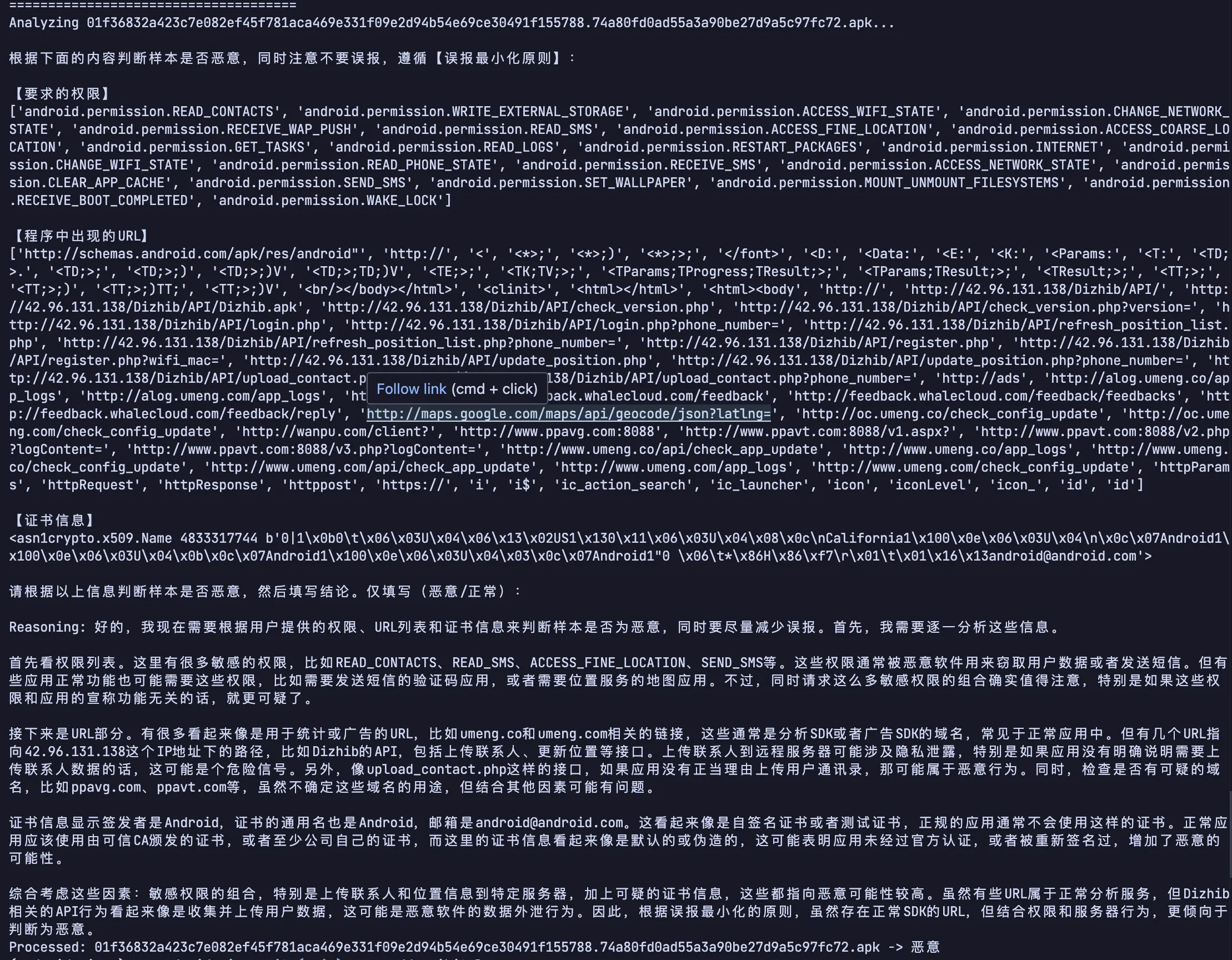
五、自动化评估脚本
from sklearn.metrics import accuracy_score, f1_score
import pandas as pd
true_labels = pd.read_csv("virustotal_report.csv")["result"].map({"Malicious":1, "Benign":0})
pred_labels = pd.read_csv("result.csv")["prediction"]
print(f"True Labels: {true_labels}")
print(f"Pred Labels: {pred_labels}")
print(f"Accuracy: {accuracy_score(true_labels, pred_labels):.2f}")
print(f"F1-Score: {f1_score(true_labels, pred_labels):.2f}")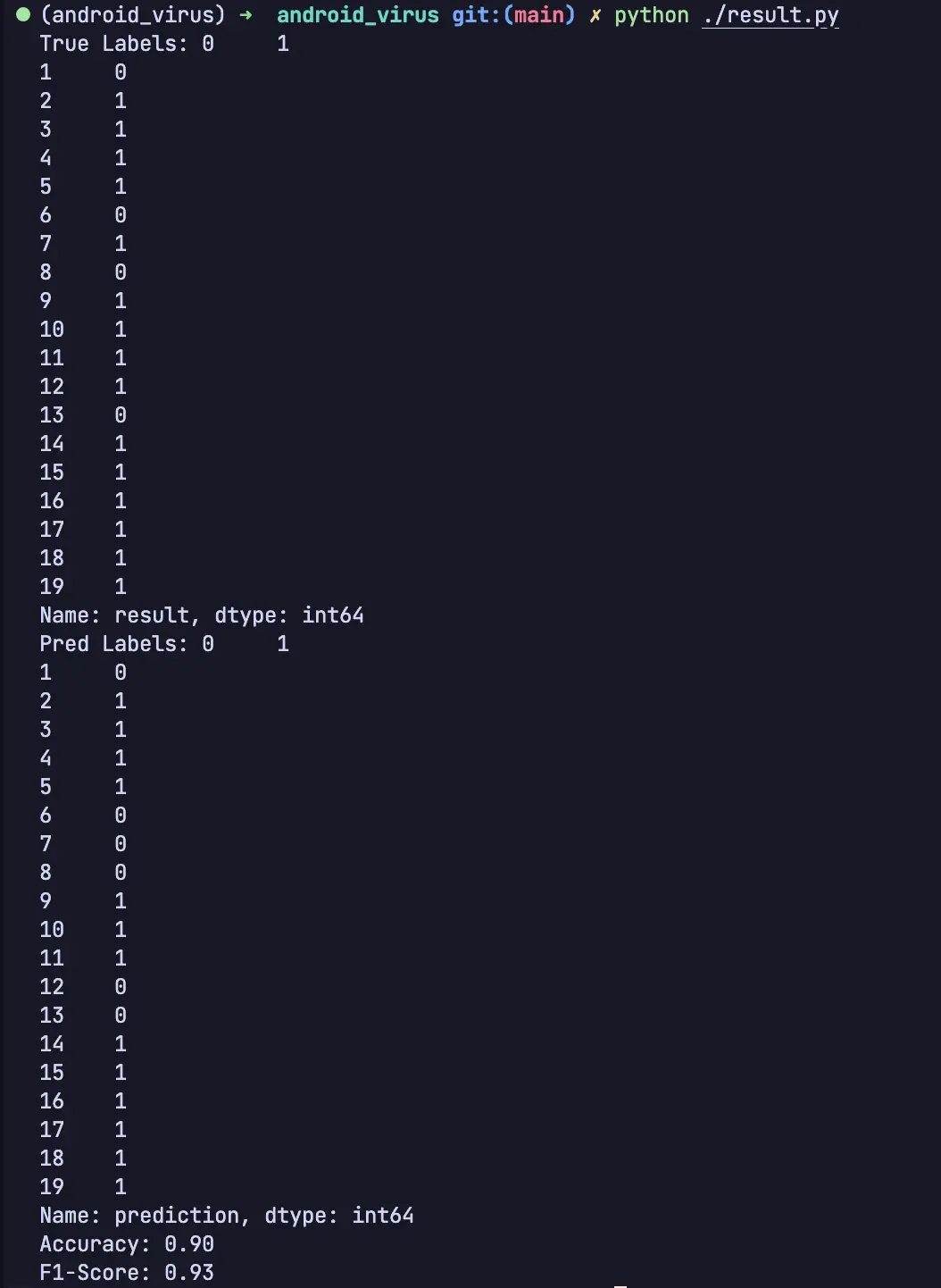
通过大模型有较高的准确率(毕竟都没有混淆过,特征还是非常明显的)