假设英文中每个字符出现的概率完全相等,并且字符之间没有任何联系的情况下,每个字符所能携带的最大信息量:
零阶近似熵
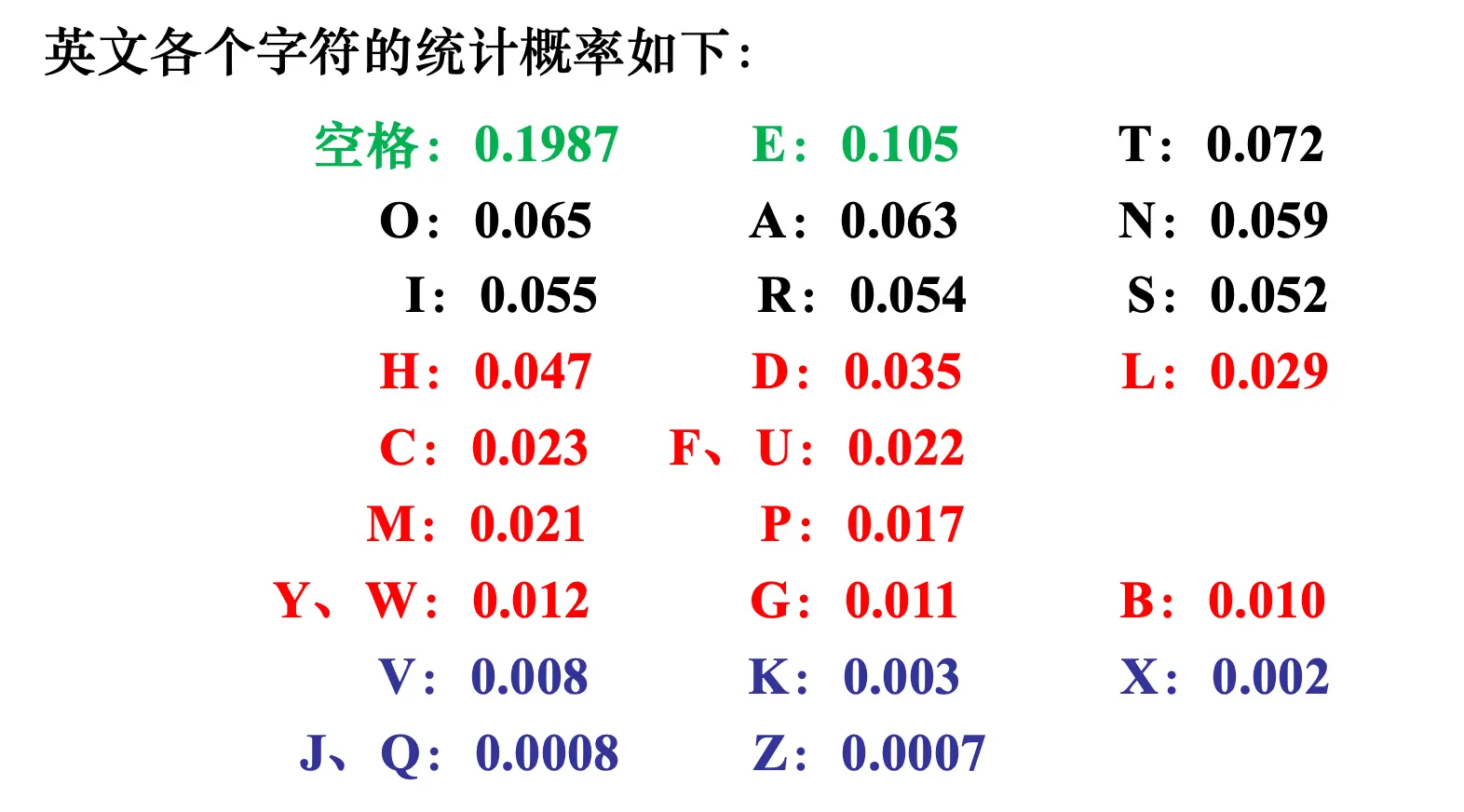
考虑英文中单个字符出现的频率,计算每个字符的平均信息量。它假设每个字符的出现是独立的,但是考虑到出现概率的差异
指向原始笔记的链接
这里的
一阶近似熵
在已知前一个字符的情况下,当前字符的 条件熵。
反映了单个字符对下一个字符的影响
同理二阶则为:
指向原始笔记的链接

信源熵的相对率
衡量信源的有效信息密度。告诉我们有多少比例的信息是“非冗余的”,越小说明可压缩性越高。
指向原始笔记的链接
信源的冗余度
指向原始笔记的链接
信息变差
只考虑单个字符频率与考虑所有上下文关联之间的信息量差异
指向原始笔记的链接